Monitoring a replica set
To learn what instances belong to the replica set and obtain statistics for all these instances, execute a box.info.replication request. The output below shows the replication status for a replica set containing one master and two replicas:
manual_leader:instance001> box.info.replication --- - 1: id: 1 uuid: 9bb111c2-3ff5-36a7-00f4-2b9a573ea660 lsn: 21 name: instance001 2: id: 2 uuid: 4cfa6e3c-625e-b027-00a7-29b2f2182f23 lsn: 0 upstream: status: follow idle: 0.052655000000414 peer: replicator@127.0.0.1:3302 lag: 0.00010204315185547 name: instance002 downstream: status: follow idle: 0.09503500000028 vclock: {1: 21} lag: 0.00026917457580566 3: id: 3 uuid: 9a3a1b9b-8a18-baf6-00b3-a6e5e11fd8b6 lsn: 0 upstream: status: follow idle: 0.77522099999987 peer: replicator@127.0.0.1:3303 lag: 0.0001838207244873 name: instance003 downstream: status: follow idle: 0.33186100000012 vclock: {1: 21} lag: 0 ...
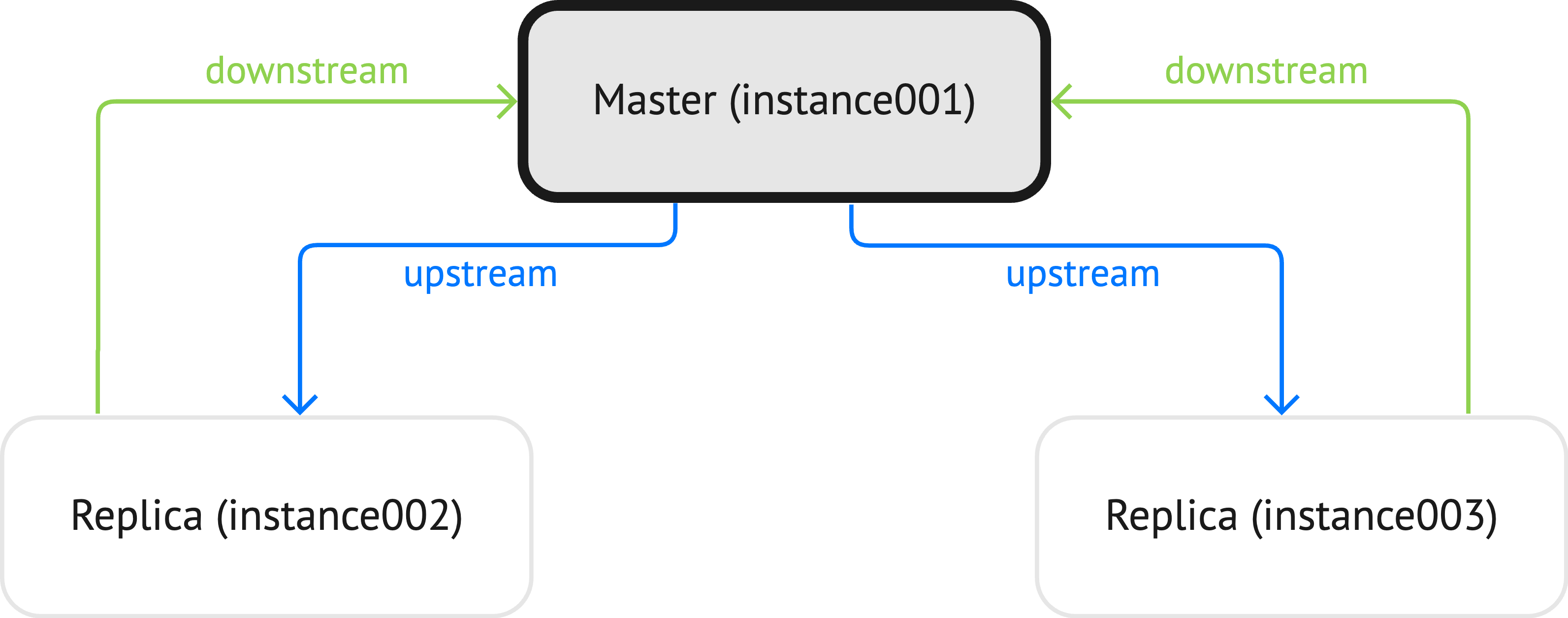
The following diagram illustrates the upstream and downstream connections if box.info.replication executed at the master instance (instance001):
If box.info.replication is executed on instance002, the upstream and downstream connections look as follows:
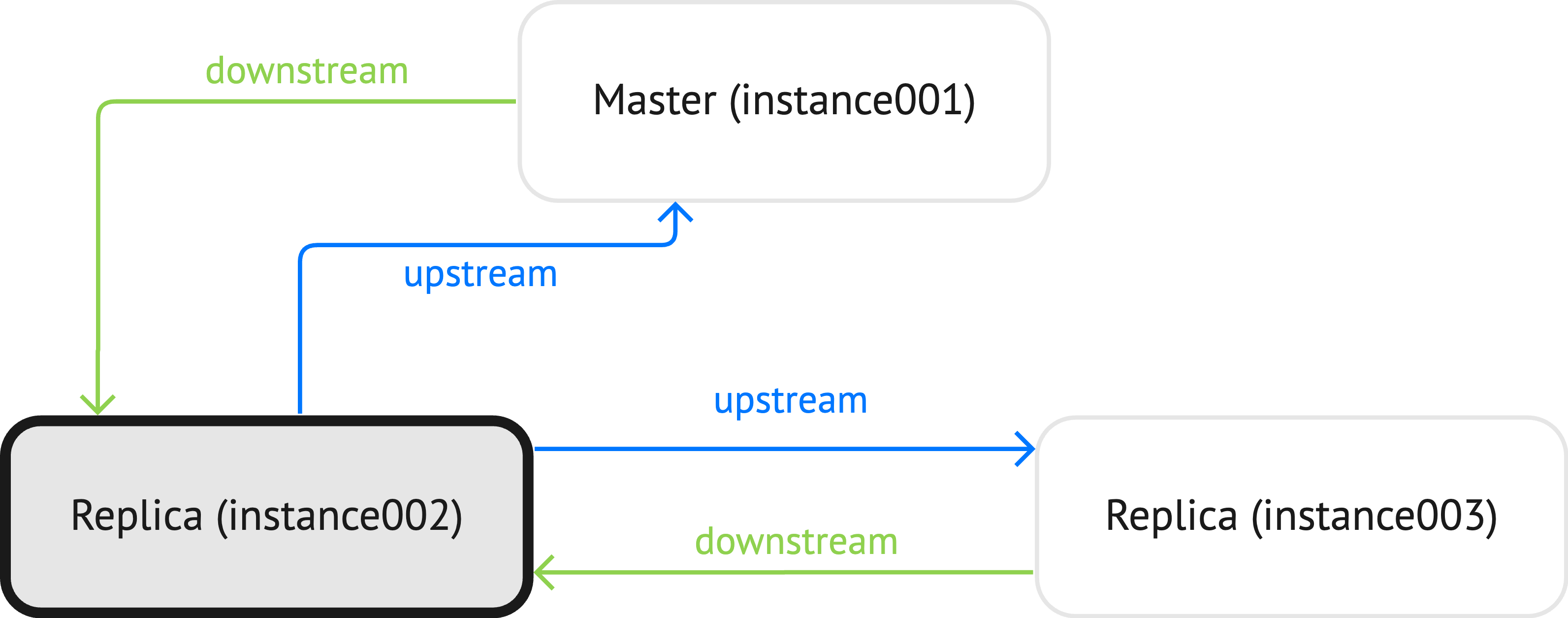
This means that statistics for replicas are given in regard to the instance on which box.info.replication is executed.
The primary indicators of replication health are:
idle: the time (in seconds) since the instance received the last event from a master.
If the master has no updates to send to the replicas, it sends heartbeat messages every replication_timeout seconds. The master is programmed to disconnect if it does not see acknowledgments of the heartbeat messages within
replication_timeout* 4 seconds.Therefore, in a healthy replication setup,
idleshould never exceedreplication_timeout: if it does, either the replication is lagging seriously behind, because the master is running ahead of the replica, or the network link between the instances is down.lag: the time difference between the local time at the instance, recorded when the event was received, and the local time at another master recorded when the event was written to the write-ahead log on that master.
Since the
lagcalculation uses the operating system clocks from two different machines, do not be surprised if it’s negative: a time drift may lead to the remote master clock being consistently behind the local instance’s clock.